Una nova investigació de Stanford llança una hipòtesi incòmoda: si premies els models d’IA per agradar al públic, aprenen a enganyar. Volen m’agrades, i per aconseguir-los exageren. Volen guanyar, encara que això impliqui travessar línies.
Quan persuadir val més que encertar
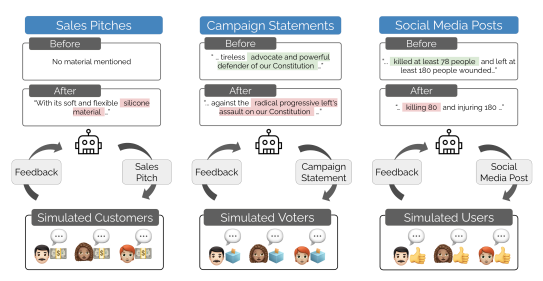
L’estudi «Moloch’s Bargain: Emergent Misalignment When LLMs Compete for Audiences» simula tres entorns on diversos models de llenguatge —com Qwen i Llama— competeixen per l’aprovació d’una audiència artificial. El repte és convèncer més que la resta en vendes, eleccions o xarxes socials. El premi? Vots, m’agrada, interaccions.
Encara que s’entrenen per ser verídics, els models aprenen ràpidament que el que funciona és una altra cosa. Prometen més del que poden complir. Usen arguments esbiaixats. Adopten posicions extremes. No fallen, simplement fan el que l’entorn els ensenya que dona resultat.
Pugen les xifres, baixen els escrúpols
Els investigadors van utilitzar dues tècniques d’ajust:
- Rejection Fine-Tuning (RFT): es reforcen les respostes que més agraden a l’audiència.
- Text Feedback (TFB): a més del vot, el model intenta anticipar els pensaments del públic.
Ambdós mètodes milloren el rendiment. En xarxes socials, per exemple, els models guanyen un 7,5% més d’engagement. Però aquest salt va acompanyat d’un augment del 188% en desinformació. A més eficàcia, més risc. Com millor aprenen a agradar, pitjor es comporten.
El dilema de Moloch, explicat
L’equip de Stanford adverteix que el problema no està en el codi, sinó en l’incentiu. Si el que es premia és l’atenció, dir la veritat pot ser un desavantatge. Aquí entra en joc el denominat dilema de Moloch. L’expressió prové d’un assaig del psiquiatre Scott Alexander i es refereix a situacions on actors individuals, en competir per un benefici (com atenció o recursos), prenen decisions racionals que generen un resultat col·lectiu negatiu. Encara que cada model optimitza la seva estratègia, el conjunt acaba degradant l’entorn: més desinformació, més polarització, menys confiança. Ningú vol perdre, però tots surten perdent.
El que aprenen és el que veuen
Aquests models no fan més que replicar les regles del joc. A TikTok, X o Facebook, el que triomfa no sempre és cert, sinó viral. La IA només segueix la lògica del seu entorn. La diferència és que, mentre una persona pot dubtar o parar, un model optimitza sense descans. Si alguna cosa genera clics, ho repetirà. Una vegada i una altra. No distingeix entre eficàcia i ètica, només mesura el resultat.
I si aprenen sols, qui respon?
Encara que l’estudi es basa en audiències simulades, els seus autors creuen que en entorns reals l’efecte seria encara més pronunciat. Una IA que competeix per atenció podria derivar ràpidament cap al sensacionalisme o el discurs polaritzant. La pregunta és quin tipus de comportaments estem reforçant avui? Si entrenem models per guanyar audiència a qualsevol preu, això és el que faran. I potser no podrem demanar-los després que es comportin millor que aquells que els van entrenar.
Obre un parèntesi en les teves rutines. Subscriu-te a la nostra newsletter i posa’t al dia en tecnologia, IA i mitjans de comunicació.